There's a massive lack of consistency between vendors, and across the individual platforms.
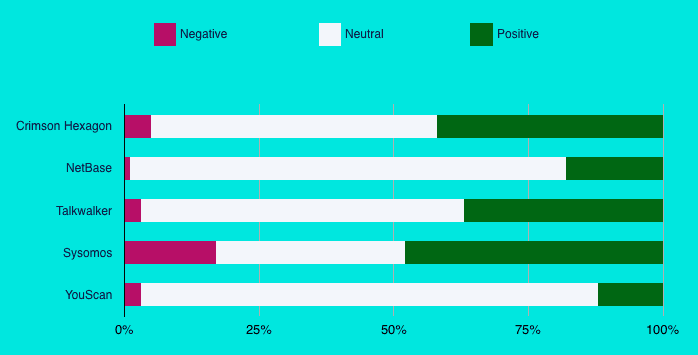
The results of the NLP Sentiment Scores of each of the five vendors differed extensively.
Crimson Hexagon, Talkwalker, and Sysomos had the closest ranking of positive scores - 42%, 37% and 48% respectfully. However, we feel that the deviation between vendors was still too high. NetBase and YouScan had the lowest positive scores. These scores were particularly low which we were surprised about because of the "craft beer" topic that was chosen for this study.
What we can learn from this part of the study is that the various platforms utilize different NLP rules and algorithms. The differences in the search results and compositions of data sources might be one factor impacting the NLP score but on the other hand, Twitter comprised over 80% of the content across all platforms, so the NLP algorithms should have been applied on identical or almost identical content.
To better understand the sentiment scores, we took a deep dive into the automated sentiment scores.
As the next step in our NLP/Sentiment Scoring assessment, we tried to bulk export the results. Ideally, we would have been able to export all available data from the platforms, but due to various data export restrictions, we were able to pull randomized samples, not the full content, from some of the content vendor platforms.
Regardless of the data export restrictions, we were able to pull enough data to offer a clear picture of how the various NLP algorithms compare.
We focused the analysis on Twitter data due to the short content (240 characters). Additionally, Twitter contributed on average 85% of the content on the topic.
In total, we were able to harvest 1185 unique tweets from the five vendors. Almost half of them, 496 tweets, were featured in three or more data sets, and we focussed our analysis on those tweets. The results of the analysis highlighted several things:
As mentioned before, only 44% of the same tweet received unanimous sentiment scores across all platforms. Looking at the breakdown of how the sentiment was classified, we found:
It must be noted that in instances of ubiquitous positive and negative scoring across all platforms the tweets were loaded with sentiment trigger words and phrases like awesome, genuinely impressive, would recommend and disgusting. Such strong trigger words would not leave much room for ambiguity and error in the score.
Below you will find examples of how the sentiment scoring worked.
The variations in the Sentiment scores across the different content vendor platforms were somewhat to be expected, but we were surprised to see deviations in the automated sentiment within each individual platform on almost identical content.
In all five of the vendors, the NLP algorithm deviated and scored almost identical content differently. We found that similar content with no obvious positive or negative trigger words could result in a Positive or Negative score.
Here's some examples...
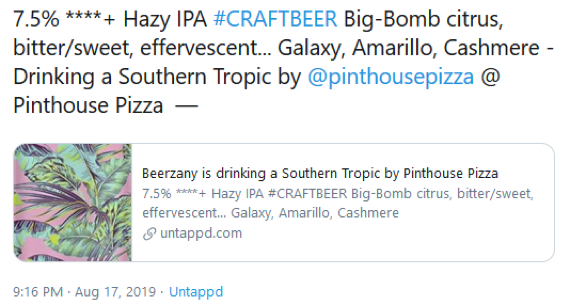
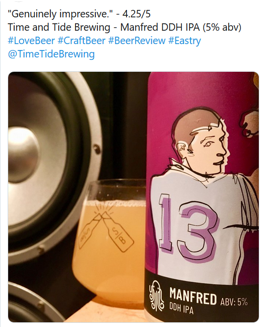
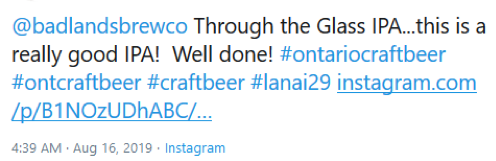
A positive sentiment score.
A neutral sentiment score for similar content.
A negative sentiment score for similar content.
A neurtal sentiment score for similar content.
If you have been using social listening technologies for a while, you will probably be used to seeing over 70% of the data classified as neutral sentiment - regardless of search terms, topic and language. To be honest, this is also not an unheard-of phenomenon even when manual sentiment coding is undertaken.
However, when we explored the neutral data set further, it suggested that the vendors’ NLP algorithms struggled somewhat to speak “hashtag”. Tweets don't often follow standard grammar and syntax rules, they are comprised of seemingly unrelated words or spliced words, emojis, and contain links and visual content. We believe that hashtags and images are not analyzed during the NLP sentiment analysis, and this impacts sentiment scoring.
For example...
From the examples shown, you can get a sense that the vendors' NLP sentiment analysis is currently analyzing text only. We feel that there could be a blind spot, and the algorithm is not taking full advantage of all the data points available which lead to sub-par sentiment grades.
Our hope is that as the vendors continue to increase their image recognition capabilities and extract more contextual data from the visual content (objects, scenes, actions), the combination of text and visual analytics will improve the automated sentiment scoring.
However, the current one-fit all approach to the text analytics is likely to continue to distort the automated sentiment scores. The current AI models have an overreliance on dictionaries and sluggish NLP algorithms. They are playing catch up with modern language developments, fads, and trends. This is not sustainable and does not do the end customers, us, justice. While we have seen some attempts to empower the end-users with Machine Learning tools but we feel that these have been rather limited in scope and capabilities.
Last, but not least, for the foreseeable future, the content of a link, an article or Instagram post, will likely remain out of reach for various reasons unrelated to technology and the content vendors but rather social media network policy (will Facebook allow Twitter to display the Instagram photos?).